去年学过一段时间的大数据开发,然而很明显这不是我想学的方向,但总还是学了些…借这个机会把学过的笔记传上来,用来增加一点文章数量。
特点
Hadoop 是一个分布式计算平台,其有如下特点:
- 高可靠性(多个备份)
- 高扩展性(扩展集群)
- 高效性(动态、并发处理)
- 高容错性(即时修复、应急处理)
- 低成本(开源、廉价机器也可运行)
- 采用优秀的 Java 语言!!
HDFS
数据存储层,分布式文件存储系统(负责集群数据的存储和读取),以主/从结构模式运行。
结构:一个NameNode,一个SecondaryNameNode,多个DataNode
NameNode
存储FSimage,处理Client的请求。
- FSimage 元数据:(1) 文件和目录的属性 (2) 文件内容存储信息 (3)所有DataNode信息
- edits:操作持久化后
对FSimage的操作会保存在内存,并被持久化到edits
启动后,FSimage加载至内存,并对内存执行edits
以上两个操作用以确保文件最新。
SecondaryNameNode
备份NameNode,将edits合并至FSimage,并取代原来的FSimage,再新建一个edits开始新的保存。
DataNode
存数据。数据以块(Blocks)的形式切割,128MB/块,每一个块都称为数据块
存储到不同的(或者相同的)DataNode并备份(一般三个)
分布式原理
分布式系统:利用多个节点共同完成一项或多项具体业务功能的系统,其划分成多个字系统或模块,各自运行在不同的机器上,子系统与模块通过网络协作实现功能。
分布式文件系统:属于分布式系统,用于解决数据存储,特点如下:
- 非单机,多个集群
- 文件分布在多个节点,并存储到副本备份
- 数据从多个节点读取
HDFS宕机处理
- 冗余备份(副本)
- 多节点副本存放
- 处理方法
- 心跳包检测,如发现损坏,直接移除该节点
- 读数据块时,如果某节点损坏,则会转移到其它节点读取
- 存数据时,如节点宕机,自动分配到其它节点读取
特点
优点:高容错性(多副本),适合大数据处理,以流式数据访问存储(一次写入,多次读取)
缺点:不适合低延时数据访问,无法高效存储大量小文件,不支持多用户写入与任意修改(不能改,只能加)
MapReduce
数据处理层,也可以叫并行计算,它是Hadoop的核心框架之一,用于大规模数据并行运算的编程模型。
两部分:Map(映射),Reduce(规约)
启动一个MapReduce任务时,Map会读取HDFS上的数据,将其映射为所需要的键值并传到Reduce端,Reduce端会接收从Map端传过来的键值对类型的数据,根据不同键进行分组,对每一组相同的键进行处理,得到新的键值对并输出到HDFS。
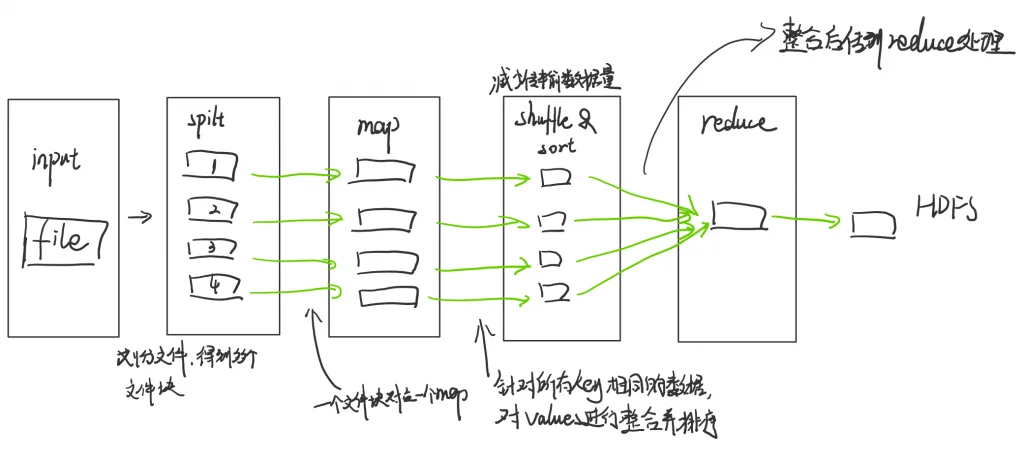
Key的值一般为每行首字母与文件最初始位置的偏移量,即中间所隔字符个数。Value的值为这一行的数据记录。

YARN
资源管理和分布式应用框架(托管平台)
目的
使Hadoop数据处理能力超越MapReduce
结构
- [M]ResourceManager:(全局)资源管理器,整个系统的资源管理分配,包含Scheduler和ApplicationsManager。
- ApplicationMaster:(每个程序特有的)应用资源,负责单个应用的管理。
- Client Application:应用程序
- [S]NodeManager:每个节点上的资源和任务管理器,不会跨节点。
行为
用户提交应用程序时,需要提供一个用于跟踪和管理这个应用程序的ApplicationMaster,它负责向ResourceManager申请资源并要求NodeManager启动可以占用一定资源的任务。
ResourceManager:ASM负责处理客户端提交的Job以及协商第一个Container以ApplicationManager运行。Scheduler负责分配系统资源给正在运行的程序。
NodeManager:定时向ResourceManager汇报节点上的资源使用情况与Container运行状态,接收并处理AM的Container的各种请求(启动/停止等)。
Container:YARN中的资源抽象,封装了某节点上的多维度资源,当AM向RM申请资源时,返回的资源便是用Container表示的。每个任务只有一个Container,该任务只能在一个Container运行。
ApplicationMaster:用户提交每个应用程序时,系统都会生成一个AM包含到程序内,作用如下:
- 与RM协商并获取资源(Container)
- 得到的任务进一步分配给内部
- 与NM通信以启动/停止任务
- 监控运行状态,并在任务失败时重新申请资源以重启Job
Client Application:客户端应用程序,在把程序提交到RM前,Client会创建一个Application上下文件对象,并设置AM必须的资源请求信息,然后提交到RM。
Flume
Flume是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据,同时对数据进行简单处理,并写到数据接收方的能力。
ZooKeeper
ZooKeeper是一个分布式应用程序协调服务。分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。同时它是集群的管理者,监视集群的状态并根据节点提供的反馈进行下一步合理操作,最终将易用的接口和高效的系统提供给开发者。